MaxCompute湖倉一體近實時增量處理技術架構揭秘 數據處理與存儲支持服務
隨著企業數據規模的爆炸式增長和業務決策對時效性要求的不斷提高,傳統T+1的批處理模式已難以滿足實時洞察、智能風控、個性化推薦等場景的需求。在此背景下,阿里云MaxCompute依托其強大的計算引擎與存儲底座,構建了湖倉一體(Lakehouse)架構下的近實時增量處理能力,實現了海量數據的高效、低延遲處理與分析。本文將深入揭秘其核心技術架構,并重點闡述其數據處理與存儲支持服務。
一、 架構總覽:融合統一的數據底座
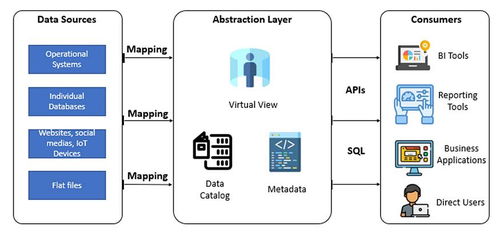
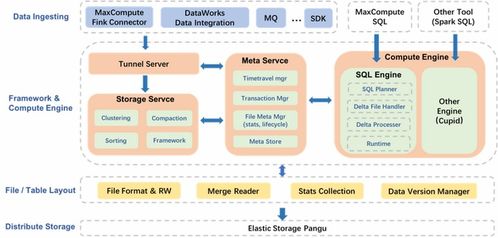
MaxCompute湖倉一體架構的核心在于打破數據湖與數據倉庫的壁壘,在同一個系統中同時提供數據湖的靈活性和數據倉庫的強大分析能力。其近實時增量處理架構主要由以下幾個關鍵部分組成:
- 統一元數據管理層:基于MaxCompute Meta服務,對存儲在對象存儲(OSS)或MaxCompute內部表(Storage)中的結構化、半結構化、非結構化數據進行統一的元數據管理,提供統一的視圖和訪問入口。
- 近實時數據攝入層:支持多種數據源(如Kafka、DataHub、Flink、Logstash等)的流式數據接入,通過內置或集成的CDC(Change Data Capture)工具,將數據庫的增量變更、日志流等實時攝入到統一的存儲層。
- 增量計算引擎層:核心是MaxCompute本身強大的分布式SQL計算引擎,結合創新的增量處理框架。該框架能夠智能識別數據分區或表的增量部分(如新寫入的文件、分區),僅對增量數據進行計算,而非全量掃描,極大提升了處理效率。
- 統一存儲服務層:作為架構的基石,它同時支持高性能列式存儲(面向分析優化)和低成本對象存儲(面向原始數據歸檔),并保證兩者之間的數據無縫流動與一致性。
二、 數據處理:高效精準的增量處理范式
MaxCompute的近實時數據處理,關鍵在于“增量”二字的實現。
- 增量數據識別與合并:系統通過追蹤數據寫入的事務日志(如Delta Log的增強實現),精確記錄每一次數據插入、更新、刪除操作。計算任務在調度時,可以基于時間戳、版本號或分區信息,準確定位自上次處理后的新增數據范圍。
- 微批(Micro-batch)與流計算融合:系統將連續的數據流切割成一系列小的、離散的數據批次進行處理(例如分鐘級或秒級)。每個微批次作為一個獨立的計算任務,利用MaxCompute的彈性資源進行快速處理。這既保證了處理的低延遲(可達分鐘級),又繼承了批處理在數據一致性、容錯性和復雜分析方面的優勢。
- Upsert與增量聚合:支持基于主鍵的Merge(Upsert)操作,能夠高效處理來自業務庫的變更數據(CDC),直接更新目標表,實現實時數倉的更新。對于需要累計算的指標(如PV、UV、GMV),系統支持高效的增量聚合計算,避免重復計算歷史全量數據。
三、 存儲支持服務:靈活、可靠、高性能的基石
存儲服務的優劣直接決定了數據處理的能力上限。MaxCompute湖倉一體的存儲支持服務展現出以下核心特性:
- 統一存儲與分層設計:數據物理上存儲在阿里云OSS或MaxCompute內部高性能存儲中,但通過統一的元數據抽象,用戶無需關心物理位置。支持熱、溫、冷數據分層存儲策略,自動將訪問頻繁的熱數據置于高性能存儲,將歷史歸檔數據移至低成本對象存儲,優化成本與性能。
- 高性能文件格式與索引:默認采用列式存儲格式(如ORC、Parquet),并支持Z-Order等多維聚簇索引,極大提升掃描與查詢性能。對于增量寫入的小文件,系統具備智能的自動合并(Compaction)能力,避免小文件過多導致的性能下降。
- ACID事務保證:存儲層提供完整的ACID(原子性、一致性、隔離性、持久性)事務支持,確保在并發讀寫場景下,特別是面對頻繁的增量更新時,數據始終保持準確性和一致性,這是實現可靠近實時處理的關鍵。
- 開放與兼容性:存儲層與開源生態(如Apache Hudi、Delta Lake的理念)深度兼容,支持開放的數據格式(Parquet等),使得數據不僅能被MaxCompute高效分析,也能被Spark、Presto等外部引擎直接訪問,避免了數據孤島。
MaxCompute湖倉一體的近實時增量處理架構,通過統一元數據、高效的增量計算引擎與強大的統一存儲服務三者緊密結合,為企業提供了一條從海量原始數據到實時分析洞察的平滑路徑。它既滿足了業務對數據時效性的嚴苛要求,又保持了處理海量歷史數據的經濟性與強大的分析能力,是構建現代數據平臺的關鍵技術選擇。數據處理與存儲支持服務作為這一架構的兩大支柱,其協同創新是釋放數據實時價值的核心驅動力。
如若轉載,請注明出處:http://www.jychem.net.cn/product/37.html
更新時間:2026-01-08 00:12:04