數據海洋的巨輪 探索全球最大的儲存服務器與配套支持服務

在當今這個數據爆炸的時代,全球每日產生的數據量高達數百億GB。為了承載這些數字世界的‘記憶’,數據中心和超大規模儲存服務器應運而生。最大的儲存服務器究竟是什么?它背后又依賴著怎樣復雜的數據處理和存儲支持服務生態呢?
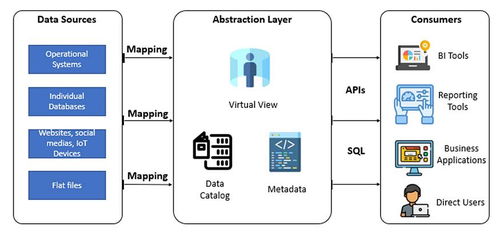
需要明確一個概念:所謂‘最大的儲存服務器’并非指單一的物理機柜或設備。在商業和科技領域,它通常指向由科技巨頭運營的、規模達到‘Exabyte’(EB,即10億GB)級別甚至‘Zettabyte’(ZB,即萬億GB)級別的超大規模數據中心集群。例如,谷歌、亞馬遜AWS、微軟Azure和Meta(原Facebook)等公司運營的數據中心,其總存儲容量難以精確公開,但普遍被認為位居全球前列。這些設施并非一臺服務器,而是由數百萬臺服務器節點、網絡設備和存儲陣列通過高速網絡連接構成的分布式系統。一個代表性的例子是Meta的‘Prineville數據中心集群’或微軟的‘Azure數據中心區域’,它們的設計目標就是提供近乎無限的、可彈性擴展的存儲容量。
支撐這些龐然大物運轉的,是一整套極其復雜和精密的數據處理與存儲支持服務體系。我們可以將其分為幾個核心層面:
- 硬件基礎設施層:這是存儲的物理基石。它包括:
- 海量存儲介質:從高密度機械硬盤(HDD)到高速固態硬盤(SSD),乃至前沿的存儲級內存(SCM),形成分層存儲體系,以平衡成本、容量和性能。
- 定制化服務器與機架:為了追求極致的能效和密度,巨頭們往往自主設計服務器主板、供電和散熱系統,將成千上萬的硬件單元高效封裝。
- 網絡神經系統:包括葉脊網絡架構、光纖通道以及最新的RDMA技術,確保數據在數百萬個組件間以微秒級速度流動。
- 軟件與系統層:這是將硬件轉化為智能服務的大腦。
- 分布式文件系統:如Google File System(GFS)及其開源仿制品Hadoop HDFS,或是更現代的Ceph、GlusterFS等,它們將物理上分散的磁盤抽象為一個統一的、容錯的巨量存儲池。
- 數據處理框架:以MapReduce、Apache Spark、Flink為代表的框架,允許對PB級數據進行并行分析和計算。
- 資源編排與調度:Kubernetes等容器編排平臺,以及像Borg(Google)、Apache YARN這樣的集群管理系統,負責高效分配計算和存儲資源。
- 數據管理與服務層:這是直接面向用戶和應用的接口。
- 數據庫服務:涵蓋關系型(如Amazon Aurora)、NoSQL(如Google Bigtable、MongoDB Atlas)和圖數據庫等,提供結構化和非結構化數據的存儲與查詢。
- 對象存儲服務:如Amazon S3、Azure Blob Storage,它們已成為互聯網上海量非結構化數據(圖片、視頻、備份)的事實標準存儲。
- 數據湖與數據倉庫:如Snowflake、Databricks、Google BigQuery,支持對海量數據進行復雜的交互式分析和商業智能處理。
- 運維與支持保障層:確保系統7x24小時穩定可靠。
- 自動化運維:通過AIops(智能運維)實現故障預測、自動修復和資源優化。
- 安全與合規:包括全鏈路加密、嚴格的訪問控制、數據脫敏以及滿足全球各地(如GDPR)的合規要求。
- 能效與冷卻:采用自然冷卻、液冷等尖端技術,并利用AI優化電力使用效率(PUE),以控制巨大的能耗成本。
因此,當我們談論‘最大的儲存服務器’時,實質上是在談論一個由尖端硬件、革命性軟件和全球性運維網絡共同構成的、不斷進化的數字基礎設施生態。它的目標不僅是‘存儲’,更是為了實現對海量數據的高效‘處理’、‘洞察’和‘價值提取’。隨著量子計算、DNA存儲等前沿技術的發展,數據存儲的形態與規模還將繼續被重新定義,但支撐其運行的服務生態——可靠、智能、可擴展——將始終是數字文明不可或缺的基石。
如若轉載,請注明出處:http://www.jychem.net.cn/product/44.html
更新時間:2026-01-08 08:54:20